Java HashMap
基础
我们先大概瞥一眼 JDK 1.7 之前的 HashMap 结构:
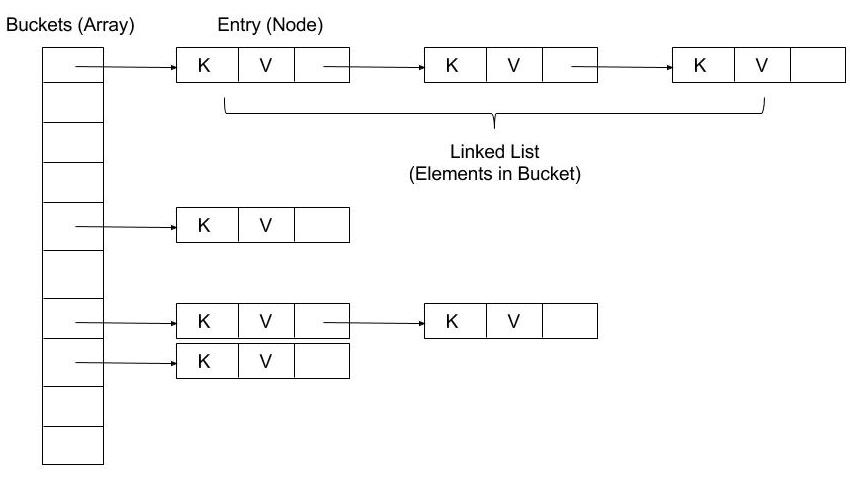
简而言之,HashMap 是由数组组成的一定数量的桶(bucket)。在进行存储时,使用 key 的 hashcode() 通过 hash 函数计算得到 hash 值,然后通过 **hash 值 % 数组长度**来确定将 Entry(key + value) 放入数组的哪个桶里。
我们先大概瞥一眼 JDK 1.7 之前的 HashMap 结构:
简而言之,HashMap 是由数组组成的一定数量的桶(bucket)。在进行存储时,使用 key 的 hashcode() 通过 hash 函数计算得到 hash 值,然后通过 **hash 值 % 数组长度**来确定将 Entry(key + value) 放入数组的哪个桶里。
Map.merge() 在键值范围中可能是功能最丰富的操作。而且还比较晦涩,很少使用。 merge() 可以解释如下:如果键值不存在(if absent),将新值放在给定键下;否则使用给定值更新现有键(UPSERT)。让我们从最基本的示例开始:计算唯一单词的出现次数。Java 8 之前的实现比较麻烦:
lambda 表达式在 Java 代码和 JVM 内部是什么样的?显然,它是某种类型的值,而 Java 只允许两种类型的值:原始类型和对象引用。lambda 显然不是原始类型,因此 Lambda 表达式必须是某种返回对象引用的表达式。
让我们看一个例子:
1 | public class LambdaExample { |
熟悉内部类的程序员可能会猜测 lambda 实际上只是 Runnable 匿名内部类的语法糖。但是,编译以上类将生成一个文件:LambdaExample.class。该类中并没有其他类文件。
Java 对象需要占用多少内存,这是一个经常被提及的问题。在缺少 sizeof 运算符的情况下,人们不禁想知道代码对其占用空间的影响。在本文中,我们将尝试窥视 Java 对象内部并查看其背后的内容。
Deeper Design and Implementation Questions (DDIQ),在某些章节中,您可能会看到其中包含有关设计/实现问题的更多讨论。这些并不能保证回答所有问题,但他们确实尝试回答最常见的问题。答案基于个人的理解,因此可能是不准确,不完整或两者兼而有之。
![]()
ElasticSearch 是基于 Apache Lucene 的分布式搜索和分析引擎,为所有类型的数据提供近乎实时的搜索和分析。
Elasticsearch 是一个分布式文档存储搜索引擎。Elasticsearch 不会将信息存储为列数据的行,而是存储已序列化为 JSON 文档的复杂数据结构。当集群中有多个 Elasticsearch 节点时,存储的文档会分布在整个集群中,并且可以从任何节点立即访问。
存储文档后,将在 1 秒钟内几乎实时地对其进行索引并可搜索。为了使文本可搜索,传统数据库每个字段存储一个值的方式不足以进行全文搜索。文本字段中的每个单词都需要可搜索,这意味着数据库需要能够在单个字段中索引多个值(在本例中为单词)。最能支持单字段多值要求的数据结构是倒排索引(inverted index),该结构支持非常快速的全文本搜索。倒排索引列出了出现在任何文档中的每个唯一值,或者词项/单词(term),并标识了每个单词出现的所有文档。
**索引(Index)**可以认为是文档的优化集合,每个文档都是字段 (field) 的集合,这些字段是包含数据的键值对。默认情况下,Elasticsearch 对每个字段中的所有数据建立索引,并且每个索引字段都具有专用的优化数据结构。例如,文本字段存储在倒排索引中,数字字段和地理字段存储在 BKD 树中。使用按字段数据结构组合并返回搜索结果的能力使 Elasticsearch 如此之快。
Elasticsearch 还具有无模式的能力,这意味着无需显式指定如何处理文档中可能出现的每个不同字段即可对文档建立索引。启用动态映射后,Elasticsearch 自动检测并向索引添加新字段。这种默认行为使索引和浏览数据变得容易-只需开始建立索引文档,Elasticsearch 就会检测布尔值,浮点数和整数值,日期和字符串并将其映射到适当的 Elasticsearch 数据类型。
但是,最终,您比 Elasticsearch 更了解您的数据以及如何使用它们。您可以定义规则来控制动态映射,也可以显式定义映射以完全控制字段的存储和索引方式。

Kafka是为了解决
系统,可以处理多种数据类型,并能够实时提供纯净且结构化的用户活动数据和系统度量指标。
数据为我们所做的每一件事都提供了动力。—— Jeff Weiner, LinkedIn CEO
Kafka 依赖于 Zookeeper 的分布式节点选举功能,安装 Kafka 需安装 Jdk、Zookeeper、Scala 组件。(Kafka 正在逐渐削弱对 Zookeeper 的依赖,逐渐演变为自管理互相发现的模式)
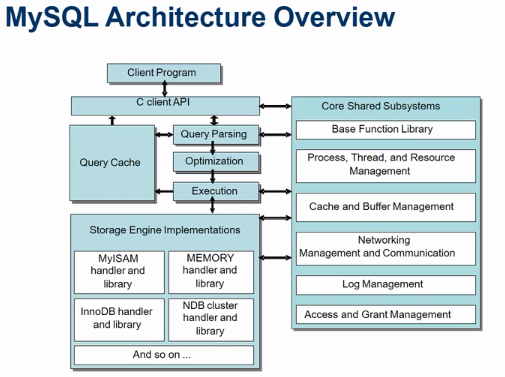
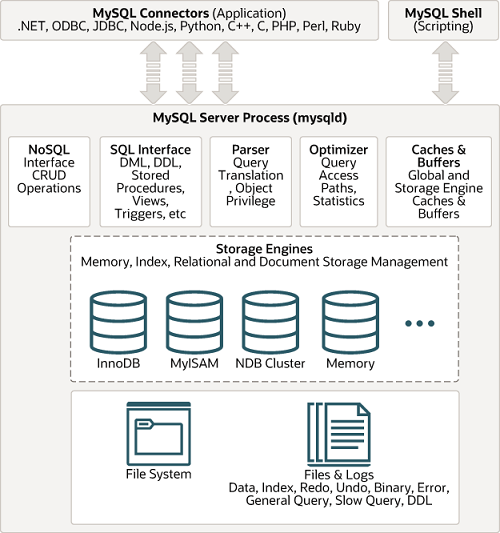
根据你的表,列,索引的细节,你的 WHERE 子句中的条件,MySQL 优化器(Optimizer) 考虑多种技术来有效地执行 SQL 查询中涉及的查找。可以在不读取所有行的情况下执行对大表的查询;可以在不比较每个行组合的情况下执行涉及多个表的连接。优化器选择执行最有效查询的一组操作称为“查询执行计划”,也称为 EXPLAIN 计划。您的目标是识别 EXPLAIN 计划中表明查询优化良好的方面,并学习 SQL 语法和索引技术以在您发现一些低效操作时改进计划。
Java 的 API 提供了很多有用的组件,能帮我们构建复杂的应用。比如日期处理,Java 从 1.0,就提供了 java.util.Date 类用于支持日期和时间的处理,不过由于该 API 设计的缺陷,产生了糟糕的易用性。随着 1.0 退出舞台,Date 类中的很多方法都被废弃了,Java 1.1 使用 java.util.Calendar 类取而代之,很不幸,Calendar 类也有类似的问题和设计缺陷,导致使用这些方法写出的代码非常容易出错。
所有这些缺陷和不一致导致用户们转投第三方的日期和时间库,比如 Joda-Time。为了解决这些问题,Oracle 决定在原生的 Java API 中提供高质量的日期和时间支持。你会看到 Java 8 在 java.time 包中整合了很多 Joda-Time 的特性。
在开始介绍日期类之前,我们先陈述几个经常出现的名次:
UTC
协调世界时,是最主要的世界时间标准,基于原子钟。
Docker 容器网络Docker 从容器中提取了基础的主机连接网络。 这样做为应用程序提供了一定程度的运行时环境不可知性,并允许基础结构管理器调整实现以适合操作环境。 连接到 Docker 网络的容器将获得一个唯一的 IP 地址,该 IP 地址可以为连接到同一 Docker 网络的其他容器进行路由。
但这种方法的主要问题是,在容器内运行的任何软件都没有简洁的方法来确定依赖的宿主机的 IP 地址,这阻止了容器将其服务端点通告给容器网络外部的其他服务。
Docker 还将网络视为第一类实体。 这意味着它们具有自己的生命周期,并且不受任何其他对象的约束。 您可以使用 docker network 子命令直接定义和管理它们。
应用程序安全性归结为或多或少的两个独立问题:
authentication/认证(你是谁?)和 authorization/授权(你可以做什么?)。
有时人们会说“访问控制”而不是“授权”,这可能会造成混淆,但是以这种方式思考可能会有所帮助,因为“授权”在其他地方可能有点言过其重。Spring Security 的体系结构旨在将认证与授权分开,并各自具有策略和扩展点。
身份验证的主要策略接口是 AuthenticationManager,它只有一个方法: